


Artificial Origin Stories
Are LLM's just ushering in a new era of NoCode tools?

My first experience with watching devs use “AI” models, or neural net driven 'intelligence’, was back in 2015. I was working as a facilitator (basically a TA except no classes or homework grading responsibilities) at the Recurse Center, an in-person hacker retreat based in New York City.
The summer I was there was a really big one for nascent LLMs. This was the time I joined a local choir and met a fellow chorister who would, weeks later, move from NYC to SF to be an early OpenAI employee (according to Wikipedia, OpenAI was founded in December 2015). A small cohort of the Recurse Center batches would form AI study groups: digging into how to train a model to win competitions.
Some of them competed in competitions, reminiscent of the Netflix prize from the decade earlier, where they’d tweak model parameters on a training dataset to try and get the best results on a competition set of data.
There were early image net productions that looked a lot like a the “Magic Eye” photos I had spent a lot of time staring into as a child had barfed up dogs. (The internet tells me these were first invented in 2015, by Google engineer Alexander Mordvintsev. More here.) These floated through the Recurse Center ecosystem, some people did projects trying to re-create them.

A few of the experiments that summer’s batch of Recursers (as we called the hackers that showed up for a batch) stuck with me.
The first was a demo of trying to get an LLM to write a computer program. I think the presenter, a young woman from Europe somewhere, showed a couple of potential programs, each with varying levels of success. I think in one it tried to build a method that would tell you if a number was odd or even. It had fifty-fifty odds of getting the right answer. It did a little bit better than that. Another, you’d draw a number on a pad of paper and it’d tell you what the number was. The last one was the game Pong.
What struck me about it, as a facilitator, who’s job it was to help people get better at the art of programming, was how much of the work that went into these LLM or “convolutional neural networks” as they were called at the time, felt like a lot of guess and check work.
These devs were thinking about probabilities and trying to shape pattern recognition out of data, but they weren’t learning much about how to actually write code that would do work on its own. Instead they massaged inputs and outputs and tried new connection topologies (mostly in Python) to see if they could get better experimental results.
I wasn’t very impressed by the code that their creations came up with. I worried these devs were substituting science projects for honing their technical craft and mastery of the primitives that would help them build “real projects”. Was that justified? Hard to tell.
(I did see one demo that impressed me: a word vector demo where you could explore topics with algebra. What happens if you add woman to crown? You get queen. Subtract the woman what do you get? A king. For some reason this did impress me, or at least I felt like it was fun to try and guess what the computer would tell me when I added or subtracted different concepts. Conceptual algebra was fun!)
No Code
Fast forward to now, the beginning of 2024. The “AI” revolution has captured the capital and mindshare of this era of Silicon Valley. It seems like every few weeks a new way to get work done, without needing to write code for yourself, pops up.
I ran across this tweet yesterday and it got me thinking about how much the new LLM interfaces all look… a lot like the “no code, Zapier” style process optimization solutions that have been popular for the last 6-8 years.
For those of you who don’t want to click, it’s a woman who wires up an AI chat bot and instructs it to call United to ask about her lost baggage. The AI is on the phone for 3hours; she finds out that she should call back in the next 48hours for an update.
The interface that she uses the schedule the task looks like a flow chart. Let’s dig into it a bit.
On the left there are two boxes. One contains the Customer Service phone line number for United Airlines.
The other is labeled “Objective” and contains a written description for the task she’d like carried out. “You are calling United Airlines to find …’s missing luggage.” And then gives the Flight number, her date of birth, and current address.
These two boxes then feed in to a “Phone Call” box, which takes a Phone Number and an Objective. Calls cost $0.010 per minute, USD. That outputs a transcript of the conversation (so the person who setup the AI to do the call can see what’s happening).
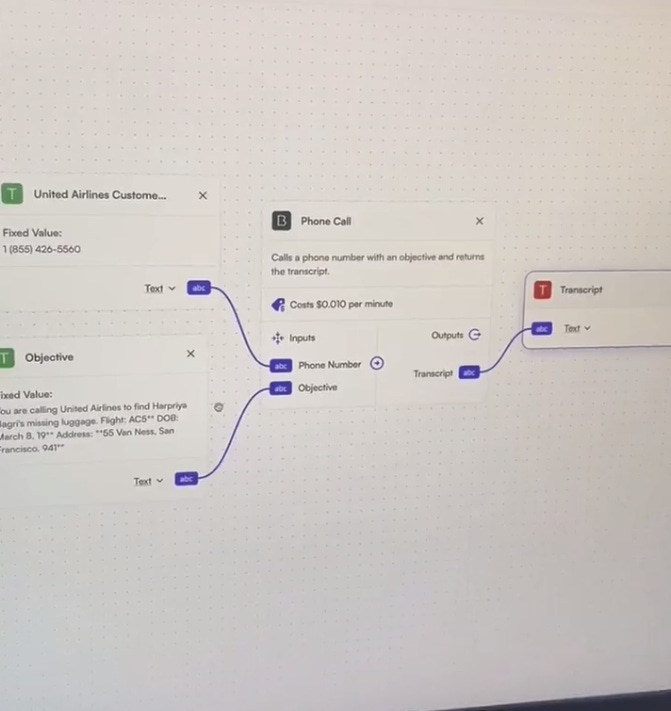
This is a lot like what the ‘no-code’ interfaces have been pioneering for ages. No code gets written, you tell the computer to execute a task with drag and drop boxes.
Tradeoffs and Leverage
I don’t really know what I’m trying to say here, other than I don’t think that developers are going away any time soon. But I’m also a little curious and wary about one more level of abstraction that we’re creating for ourselves between what we want to happen and what we’re capable of requesting.
I think the thing I like about code as an object is your ability to inspect what you expect to happen, and the repeatability that you’re (roughly!) guaranteed. Once you have the right code written, in theory you should be able to re-execute it and get the same or similar results every single time. For infinity.
It’s also inspectable. You can drill down into what’s happening, place debug statements. Typically the levers you have to pull for what you change are extremely granular — the system is malleable at a low-level and understandable. By spending time with expert crafted code systems, you learn more about how reality works. It gives you tools to become more powerful.
With projects that use LLMs, you’re at a bit of a disadvantage. You can’t replicate, exactly, the result that you get out of these neural network systems. There are less levers for changing them but rather rhetoric and dialog. You have to hone your description and narrative building skills to communicate more finely with the LLMs.
They use probabilities under the hood to generate new results; inspecting what particular path through its weights that any single query took isn’t something you can just do.
And in fact, if you dig into the deep neural net literature, it’s a well known secret that these nets are black boxes — most people aren’t really sure how or why they work. Instead, users become alchemists that attempt different inputs to get back something different.
Not to say that they don’t have their uses. I would 100% use one to avoid sitting on a phone for a few hours, only to get told to repeat the process again, 48 hours later.
In Exitus
LLMs are gasoline on the no-code fire. I think it’ll just end up in more weird bureaucracy for all of us: generating reams of content that other agents will read, answering phone calls that other agents place.
At some level, maybe we should turn those interactions into API calls, but instead of doing that we left the “human designed” interface in place and instead built more complicated machines that can access it.